|
Iguana 1.0.0
Implementation Guardian of Analysis Algorithms
|
|
Iguana 1.0.0
Implementation Guardian of Analysis Algorithms
|
![]()
This documentation shows how to use the Iguana algorithms. For more documentation, see the Documentation Front Page
| Quick Links | |
|---|---|
| List of All Algorithms | List of Algorithms Organized by Run Group, etc. |
| List of Action Functions | Configuring Algorithms |
| Banks Created by Iguana | Examples of Code |
To see Iguana algorithms used in the context of analysis code, with various languages and use cases, see:
| Examples | |
|---|---|
| C++ Examples | For users of ROOT, clas12root, etc. |
| Includes guidance on how to build Iguana with your C++ code | |
| Python examples | For users of Python tools, such as PyROOT |
| Fortran examples | See also the Fortran usage guide |
| Java | We do not yet support Java, but we plan to soon |
In summary, the general way to use an Iguana algorithm is the following:
Please let the maintainers know if your use case is not covered in any examples or if you need any help.
Here is a flowchart, illustrating the above:
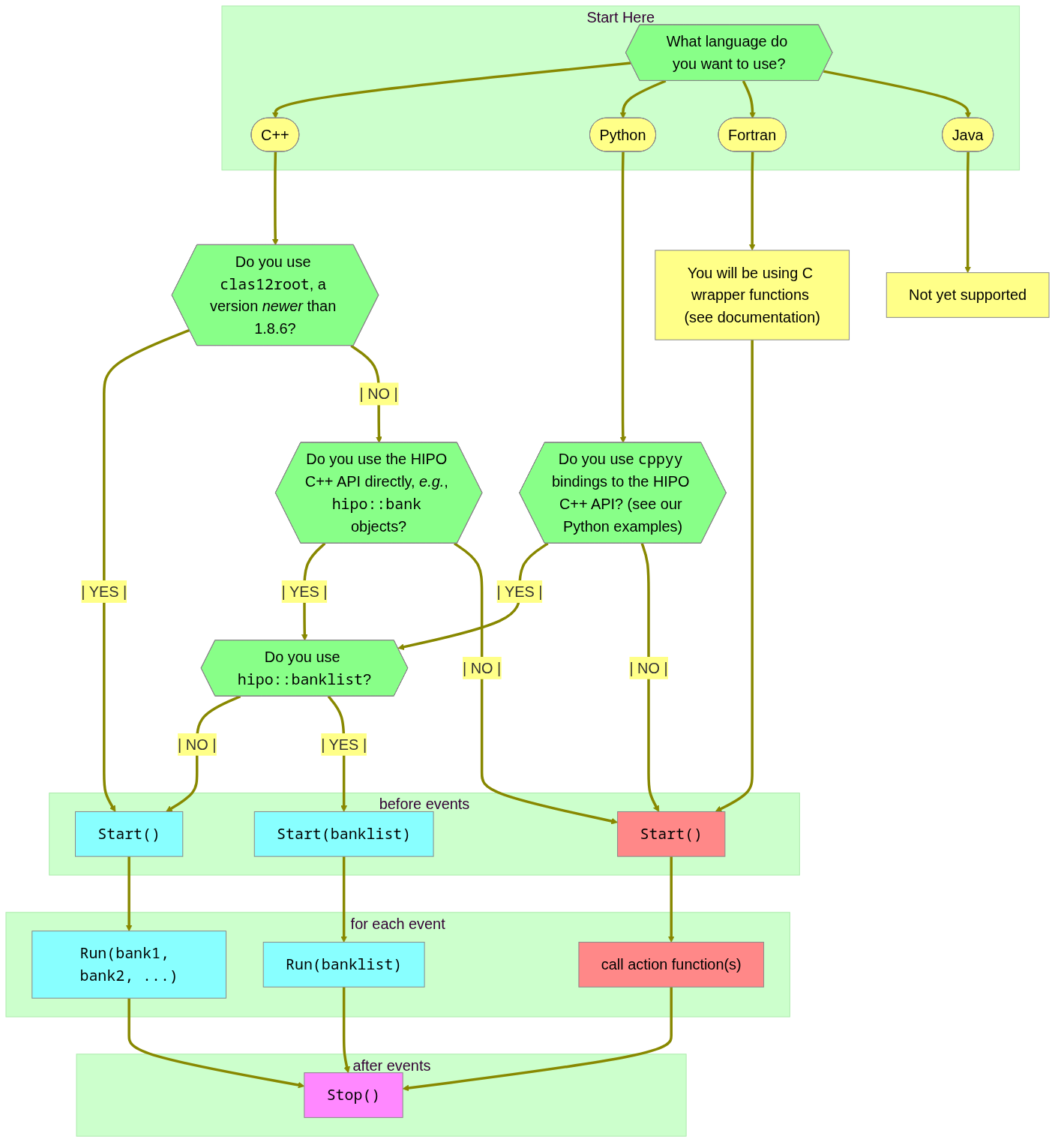
An Iguana algorithm is a function that maps input HIPO bank data to output data. There are a few different types of algorithms, based on how they act on HIPO data:
| Type | Description | Example |
|---|---|---|
| Filter | Filters rows of a bank based on a Boolean condition | iguana::clas12::rga::FiducialFilterPass2: filter particles with fiducial cuts |
| Transformer | Transform (mutate) elements of a bank | iguana::clas12::rga::MomentumCorrection: correct particle momenta |
| Creator | Create a new bank | iguana::physics::InclusiveKinematics: calculate inclusive kinematics \(x\), \(Q^2\), etc. |
The available algorithms are:
Algorithms may be run using one of the following; see the usage flowchart for help deciding what to do.
The next sections describe each of these.
All algorithms have the following Common Functions, which may be used in analysis code that uses the HIPO API. These functions act on hipo::bank objects, and are designed to be called at certain points in an analysis of HIPO data:
| Common Functions | |
|---|---|
| Start | To be called before event processing |
| Run | To be called for every event |
| Stop | To be called after event processing |
The Run function should be called on every event; the general consequence, that is, how the user should handle the algorithm's results, depends on the algorithm type:
| Type | How to handle the results |
|---|---|
| Filter | The involved banks will be filtered. To iterate over filtered bank rows, use the function hipo::bank::getRowList, rather than iterating from 0 up to hipo::bank::getRows(). For example, given a bank object named particle_bank: for(auto const& row : particle_bank.getRowList()) {
// loops over only the rows which pass the filter
}
for(int row = 0; row < particle_bank.getRows(); row++) {
// loops over ALL rows, regardless of whether they pass the filter
}
|
| Transformer | The transformed hipo::bank will simply have the relevant bank elements changed. For example, momentum correction algorithms typically change the particle momentum components. |
| Creator | Creator-type algorithms will create a new hipo::bank object, appending it to the end of the input hipo::banklist.
|
Internally, Run(hipo::banklist&) calls Action Functions, which are described in the next section.
The action functions do the real work of the algorithm, and are meant to be easily callable from any analysis, even if HIPO banks are not directly used. These functions are unique to each algorithm, so view the algorithm documentation for details, or browse the full list:
Action function parameters are supposed to be simple: numbers or lists of numbers, preferably obtainable directly from HIPO bank rows. The return type of an action function depends on the algorithm type:
| Algorithm Type | Action Function Output |
|---|---|
| Filter | Returns bool whether or not the filter passes |
| Transformer | Returns the transformed parameters |
| Creator | Returns a simple struct of parameters (corresponding to a created bank row) |
Some algorithms have action functions which require a number from all of the rows of a bank; this distinction motivates further classification of action functions:
| Action Function Rank | Description |
|---|---|
| Scalar | Outputs are scalar quantities (single values). This type of function typically may be used on a single bank row. |
| Vector | Outputs are vector quantities (lists of values). This type of action function typically needs values from all of the bank rows. |
Note that the action function parameters may be scalars and/or vectors, i.e., 0-dimensional or 1-dimensional.
To maximize compatibility with user analysis code, these functions are overloaded:
Finally, it is important to note when to call action functions in the analysis code. For example, some action functions should be called once every event, while others should be called for every particle of the REC::Particle bank. Some algorithms have both of these types of functions, for example:
It is highly recommended to read an algorithm's documentation carefully before using it, especially if you use action functions.
Many algorithms are configurable. An algorithm's configuration parameters and their default values are found in the algorithm's documentation.
Iguana provides a few ways to configure algorithms; in general, you may either:
The default configuration YAML files are installed in the etc/ subdirectory of the Iguana installation. If you have set the Iguana environment variables using, e.g. source this_iguana.sh, or if you are using the version of Iguana installed on ifarm, you will have the environment variable $IGUANA_CONFIG_PATH set to include this etc/ directory.
There are a few ways to configure the algorithms with YAML; see the sections below for the options
Start your own YAML file by first copying the default YAML configurations from each algorithm that you want to use. See algorithm documentation or the Config.yaml files installed in $IGUANA_CONFIG_PATH for the algorithms' default YAML configurations.
For example, suppose you want to use algorithms which have the following YAML configurations:
Custom YAML file, with some changes such as widening AlgorithmA's cuts:
Once you have a YAML file, you just need to tell each algorithm to use it:
First, copy the default configuration directory to your work area, or to your analysis source code; we'll call the copied directory my_iguana_config, as an example. If $IGUANA_CONFIG_PATH is the default configuration directory (i.e. you have not set or modified this variable yourself), you may run:
You may then freely modify any configuration file within my_iguana_config/.
To use this directory in your algorithms, you may do any one of the following: